Part of the GIMP is about digital image creation, but much more is about digital image manipulation. One of the primary problems in any project, then, is finding the necessary raw materials: the digital images to be manipulated.
There are many sources for digital images. A scanner is one possibility. However, some care must be exercised, because fair use rules can be a little tricky concerning copyrights . It is particularly recommended that caution be used when using an image of a recognizable person or any trademarks or company logos. These sorts of images are often aggressively protected, even for noncommercial use.
Of course, scanning one's own photographs is an excellent source of material. If you don't have ready access to a scanner, photo-CDs are a relatively inexpensive way of having your photographs professionally scanned and saved in a convenient storage medium. Digital cameras are also excellent tools for getting the pictures you need. Many good-quality, low-priced digital cameras are now available. A major advantage of a digital camera is that photos can be taken and immediately evaluated. Thus, if the photo doesn't quite have the desired qualities, it can be taken again, until the right subject matter is created. Several of the images used in this book were obtained this way.
Nevertheless, it is often inconvenient or just impossible to personally take photos of some subjects--pictures of frosty icebergs at the South Pole, a Bengal tiger in its natural habitat, the space shuttle in orbit. Most of us just can't go there to get the shot. Let's not despair, though. There is a treasure-trove of free photographic material on the Internet, and all of the above and much more can be found with a little effort. The secret is that many United States government web sites have no-copyright-assertion policies. This means that most of the photos on these sites can be freely used both commercially and noncommercially.
Examples of excellent sources of large, free image archives can be found at web sites for the National Aeronautics and Space Administration (NASA), the National Oceanic and Atmospheric Administration (NOAA), and the U.S. Fish and Wildlife Service (FWS). These all have terrific image libraries containing tens of thousands of images of animals, plants, underwater life, space, planes, ships, and so on. The following is a list of web sites that are the starting points for exploring some of these image collections. Just remember that there are some restrictions, and the responsibility of ascertaining the copyright of each image remains with you. Make sure you read the copyright claims on each site before using images found there.
Much of the raw photographic image material used in this book comes from three main sources. NASA has several excellent sites housing image collections. Here are the three I made the most use of:
http://www.nasa.gov/gallery/photo http://images.jsc.nasa.gov http://nix.nasa.govI have also made heavy use of the NOAA's main photo site, which can be found at
http://www.photolib.noaa.govThe U.S. FWS also has a terrific photo library located at
http://pictures.fws.gov
The convention used in this book for crediting photos taken from these sites is to give the complete URL of the image the first time it appears in the book. This not only credits the image source, but can also be used by the reader to directly access the photo from the Internet.
There are many more U.S. government services that provide some or all of their imagery free to the public. The U.S. Navy and Air Force, the Library of Congress, the U.S. Geological Service, and many more have web sites with images free for public use. Although these sites offer large, useful collections of images, it is sometimes frustrating browsing their sites, trying to find the right image for a special project. A solution is to download the entire site using web-mirroring software. The images can then be extracted and placed in a separate directory. This creates a personal image library that is much easier to browse than it would be online.
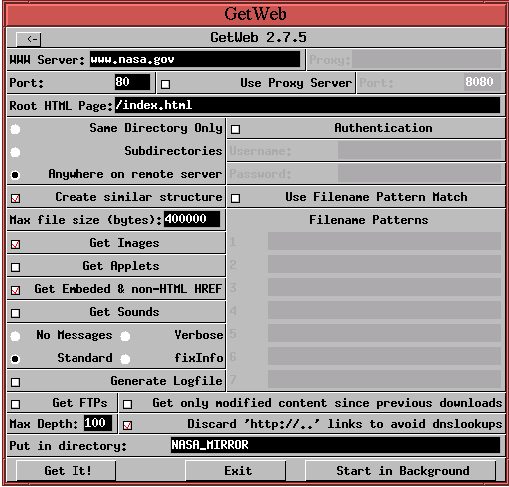
There are several free web-mirroring programs available. The one I
use is called GetWeb , and its homepage is at http://www.enfin.com/getweb/index.html.
Figure 5
GetWeb downloads a web site to the specified local directory, while maintaining the relative directory structure of the mirrored site. If the root of the local directory is called MIRROR, a bash shell script that can be used to cull all the JPEG image files might be:
#!/bin/bash
mkdir IMAGES
find MIRROR -name "*.jpg" -exec mv {} IMAGES \;
You would use the script by moving it to the directory
containing MIRROR and running it there (it might be necessary to
make the script executable with the UNIX chmod command). This
would produce the new directory named IMAGES containing all the
JPEG files.