MCOP does a number of things for you. What probably impacts the way you work with multimedia objects most is the network transparency every MCOP object gets. You can interact in the same way with MCOP objects whether they are executed in the same process, in a different process on the same computer, or on a different computer. In any case, MCOP objects are more than just C++ objects. So now I'll describe the details you need to know when using MCOP. The interface definition language (IDL) serves one purpose: defining which interfaces certain objects offer. In contrast to "normal" C++ classes you define when programming C++ applications, all interfaces you define in MCOP IDL are supposed to be network transparent. For that reason, it is not possible, for example, to simply make a function in an interface that returns a void-pointer. The same is valid for parameters. Also, you can't simply say, "Well, this function takes a block of data of 1024 bytes," because depending on what you put into that block, the different byte order on different machines would make your interface not work correctly across the network. So what definitions can you actually put into your IDL files? #include statements that include other .idl files Custom data types that are either Interfaces, which may inherit other interfaces and contain the following: Methods that work with some well-known types Streams, such as audio streams, event streams, or byte streams Attributes
Let's start with includes. They look like and will be searched in all paths you gave to mcopidl with the -I option. Their purpose is to ensure that mcopidl knows each type (and can decide if, for instance, User is an interface, a structure, or an enumeration value). Including files will generate a corresponding #include in the generated C++ source. That means if example_add.idl includes artsflow.idl, example_add.h will also include artsflow.h. Then, there are the capabilities to define custom data types. The easiest are enumeration values (with the same syntax as in C++), for instance (taken from core.idl): Also, very similar to the C++ syntax are structs, such as The simple types you can use are long, string, float, byte, boolean, and it is also possible to write sequence<sometype> to get a variable size sequence (which roughly corresponds to arrays/pointers in C++). All type concepts are there only to make defining interfaces with methods and attributes possible in a reasonable way. As I said earlier, because any MCOP interface should be network transparent, MCOP must know what types you pass around and how to deal with them. So here is how you do interfaces, first of all, with simple methods: As you see, you can pass structures to methods, the same as you can pass normal values. The same is true for the return code. It is also possible to pass object references (simply by specifying the name of an interface as return code or parameter). You can also have oneway methods, which provide send-and-forget behavior. However, note that calling a oneway method returns immediately, so you can't rely on the fact that the method is done when your code goes on. Here is a oneway method: Finally, there are attributes, which are declared as follows: Here you see that there are two types of attributes: those that can be read and written and those that are read-only. It makes sense that for an X11 window, for instance, the window handle can only be read, whereas the position and size could be modified by writing the attribute. Here is a look at the C++ code necessary to read/write attributes: Now to the last part—the most important part, streams. The syntax for defining streams is Table 14.1 explains the stream's syntax.
Table 14.1. Defining Streams in the.idl File | Element | Description |
|---|
| [ async ] | Used to make a stream asynchronous. Asynchronous streams are those that transfer data only sometimes—not continuously—or that can't always produce data when you ask them to. More about that in the section "Synchronous versus Asynchronous Streams." | | in/out | This gives the direction of the stream: incoming or outgoing | | [ multi ] | Used to say that this stream can accept multiple connections. For instance, if you have a mixer that can mix any number of audio signals, it would have a multi-input stream. There are no multi-out streams. | | type | The data type that gets streamed. Audio is a way to say float, because all audio data will really be passed around as floats. Not all data types are allowed for streaming | | stream | This means that you want to declare a stream. | | name | The name of the stream. You can define many streams at once (if they have the same parameters) by giving more than one name here. |
The normal streaming type you'll mostly use is audio (and this is a synchronous stream). Internally, this audio data is represented as float. Mostly, you'll define streams as shown next: If you inherit from an interface that already has streams, it may even happen that you don't need to add anything at all; for instance: In this example, appropriate streams are inherited from StereoEffect. | |
The IDL compiler is easy to use. It is called as shown next: flags specify the flags used when processing the IDL file. The IDL compiler then creates file.cc and file.h, which contain the necessary classes to enable network transparency, scheduling, and other gimmicks. With the -I flag, you can add include paths to search. If you want to add multiple paths, use -I more than once. If you want to integrate an mcopidl call into the make process, the following (which can be used to build the example mentioned previously) could be some inspiration: Of course, you'll need to adapt that a bit. For Automake, for instance, it's a good idea to put example_add.cc/example_add.h in the metasources section. | |
When you write in your source code, you create a reference to a Synth_PLAY object, not a Synth_PLAY object itself. What happens is that as soon as you actually try to use p, an implementation is created for you. That happens, for instance, as soon as you write Because this is only a reference, writing things such as doesn't create a second Synth_PLAY object, but only makes q point to the same object as p. MCOP keeps track of how many references point to a certain object. If this count goes to zero, the object is freed. Thus, you never need to care about pointers when using MCOP objects, and you also don't need the new or delete operators. One of the nice things is that this reference counting works even in the distributed case. If you have a server process that hands out an object reference to a client process (for instance, as return code), the object on the server will not be freed, unless the client no longer holds references to the object. MCOP is so smart that it recognizes client crashes. That means if you (as server) create an object specifically for one client and that client doesn't need it anymore (or crashes), the object will be removed. Of course, this works only if you don't hold any references to the object yourself inside the server. | |
When you have everything—interface definitions, implementations, and a server (for instance a soundserver), how does the client start talking to the interface? For this problem, the MCOP object manager (which you can access with ObjectManager::the()) provides these functions: With addGlobalReference, you can say, "I have implemented an object, and everybody can use it under the name…." For instance, the aRts soundserver artsd makes a SimpleSoundServer interface available under the name Arts_SimpleSoundServer. With getGlobalReference, you can get a string that you can convert into an object reference again. And finally, removeGlobalReferences can be used to remove all global references you have added. These global references are shared among all MCOP-aware processes. There are currently two strategies of doing so. Either in the /tmp/mcop-username directory or on the X11 server. Whichever one is used depends on the user's configuration. The following is a very useful shortcut to getting global references: After these lines, you can use the SimpleSoundServer as if it were a local object. For instance, call and your requests will be sent to the artsd soundserver. | |
Most of the time when you're dealing with streams, you'll write calculateBlock implementations. And most of the time when you write those, they'll access only synchronous audio streams. In that case, the only thing you need to do is to process all samples you read from the streams—for instance, in one for loop like the following (from our Example_ADD from the beginning): As you see, the streams have been mapped to simple float * pointers by the mcopidl compiler. In your calculateBlock function The scheduler will supply you with samples input values. You must fill all output streams exactly with samples values (if you have nothing to write, write 0.0 values instead). You may not modify the pointer itself.
For multiple input streams (which are declared with the multi keyword in the IDL), the mapping isn't float *, but float **. When calculateBlock is called, the float ** will point to an array of float * buffers, and the end is marked by a null pointer. So you can use a code fragment like that to process multi-input streams: Here, the same rules as those for single streams apply, with the addition that | |
Module initialization and deinitialization happens through a number of ways. They are chronologically listed here. As most modules don't need all the initialization facilities provided by the SynthModule interface, a small class has been written that implements all of them as empty methods. Thus, you can rewrite only the parts you need while leaving, for instance, streamStart() untouched/empty. It is called StdSynthModule, and it gets used through inheritance, such as the following (example from synth_add_impl.cc): First, , there is the traditional C++ constructor. You can use this as always—to allocate resources that your module will need in any case, to initialize members with certain values, and so on. | |
Later on, the user of the module (or some automatic mechanism, such as the flowgraph based initialization artsbuilder will do) will set the attributes. You should accept all changes there in any order. For instance, if your module relies on a filename attribute and a format attribute, it is a valid usage of your module, first to set the filename, then the format, and then choose another filename again. Also, querying your attributes at that phase should return sensible values. artsbuilder will provide some RAD-like component development, so your modules should be configurable gracefully and fully over the attributes (and not over special initialization functions). Setting and getting attributes is valid at any point in time between the constructor and destructor, especially while the module is running. | |
After all attributes have been set completely, the streamInit() function is called (before your module is started). In that function, you should do all that is necessary before actually starting. For some modules, a difference exists between that initialization phase and actually starting. For example, consider the sound card I/O. In the streamInit() function, it opens the sound card, sets the parameters, allocates the buffers, and prepares anything. | |
Finally , in streamStart() only the last bit is done. In the case of our sounddriver, only the IOManager registration is done, which actually causes writing. The idea is that initialize should do all operations that may take longer (for instance, allocating and filling a 16KB buffer may, under ugly circumstances, take longer because it needs to get swapped in first). On the other hand, registering an I/O watch should be fast. After streamStart() has been called, the module will be ready to go. The calculateBlock function gets called as soon as the scheduler thinks it is necessary. | |
Finally , when your module gets stopped, streamEnd() is called. That function should undo all effects caused by streamStart() and streamInit(). Note that the scheduler may decide not to free your module immediately, but to fill it with new attributes and use it again for some other task. Therefore, don't do things in the constructor/destructor that really belong to streamInit()/streamEnd(). | |
Eventually, when everything is done, the C++ destructor gets called, where you can free things you have set up in the constructor. | |
| |
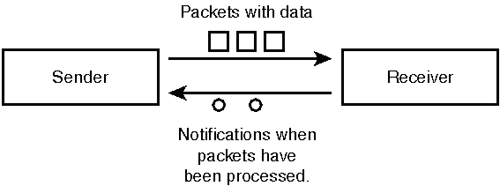
Synchronous streams are used whenever samples are happening at periodic time intervals and your module can, when given a certain amount of input, guarantee producing the same amount of output. For most modules, such as those that add signals or process them with other calculations, this should be no problem. However, modules that depend on external resources, such as the piano player that generates the MIDI events or the network connection that supplies the data, can't make such guarantees. The same can be true for consuming data as well. Modules that depend on the external network connection to receive everything they send can make only limited guarantees that the data you feed into them really disappears. Thus, asynchronous streams offer a greater amount of control. They send around the data in packets. The basic idea is this: the sender sends packets, and the receiver receives packets and acknowledges when they have been processed completely (see Figure 14.5). There are now two basic forms of behavior for a sender: push delivery and pull delivery. Push delivery occurs when the sender only casually generates a data packet. This is true, for instance, for a MIDI receiver connected to an external MIDI keyboard. Events are generated only when the human player plays some notes. The MIDI sender can assume that in this case it can simply put things into packets and the receiver should be able to process what it gets in time. The API for doing so is simple: suppose the stream is called outdata, and the datatype that is being sent is byte: As you can see, you can shrink the size of the data sent after allocating the packet. The purpose of this is that you can use system functions such as read() or write(), for instance, directly on the buffer inside the data packet and, after that, decide how many of these bytes should be sent. Sending data packets with zero length frees them immediately. Now to the other case, that happens if you want to send a sample stream of bytes asynchronously from inside an application (such as the game Quake) to the soundserver. There you want synchronization with the receiver; that is, you want to send packets only as fast as the receiver processes them. Push delivery works like that: you get calls from the scheduler when you should produce packets. To initialize the process, you ask the scheduler to prepoll x packets with the size y. Then it will ask you x times to fill such a packet. They are sent to the receiver(s). When they have processed them, they will come back, and you will be asked to refill the packets. Starting the process happens with something like the following: After that call, you'll be asked eight times to refill a packet of 1024 bytes. These packets will be sent to the receiver(s). After they have processed the packets, you'll get new requests to refill packets. Thus, the only thing you need to get this working is a refill routine: and that is it. For the receiver, things are even simpler. As soon as it gets packets, the process_streamname function is called, and it should call packet->process as soon as it is really done processing a packet. A process function for a byte stream that prints everything to stdout would be: The receiver may delay the process called and do it some time after the process_streamname function, as well, if that is when the packet is really processed. | |
Objects can be connected with the connect() function, which is declared in connect.h. The concept of default ports plays a certain role here. The standard syntax for connect is However, this can be simplified when the objects have suitable default ports. For instance, all objects with only one incoming/outgoing stream default to using them in connect, so that the following connect operations are the same: For modules with more than one port, default ports usually work as well (for example, Synth_PLAY with invalue_left and invalue_right defaults to using both as default ports). You can find exactly which modules they are for with the help of the IDL files. Under the node()/_node() accessor of every SynthModule is a more complete API for modules. There, the connect/disconnect/start/stop functions are defined. At the time of this writing, MCOP is still a work in progress. Probably, disconnect and stop will be available soon under stop() like start() and disconnect() similar to connect() with default ports and anything else. | |
| |